
Expert Assignment Solutions with 100% Guaranteed Success
Get Guaranteed success with our Top Notch Qualified Team ! Our Experts provide clear, step-by-step solutions and personalized tutoring to make sure you pass every course with good grades. We’re here for you 24/7, making sure you get desired results !
We Are The Most Trusted
Helping Students Ace Their Assignments & Exams with 100% Guaranteed Results
Featured Assignments
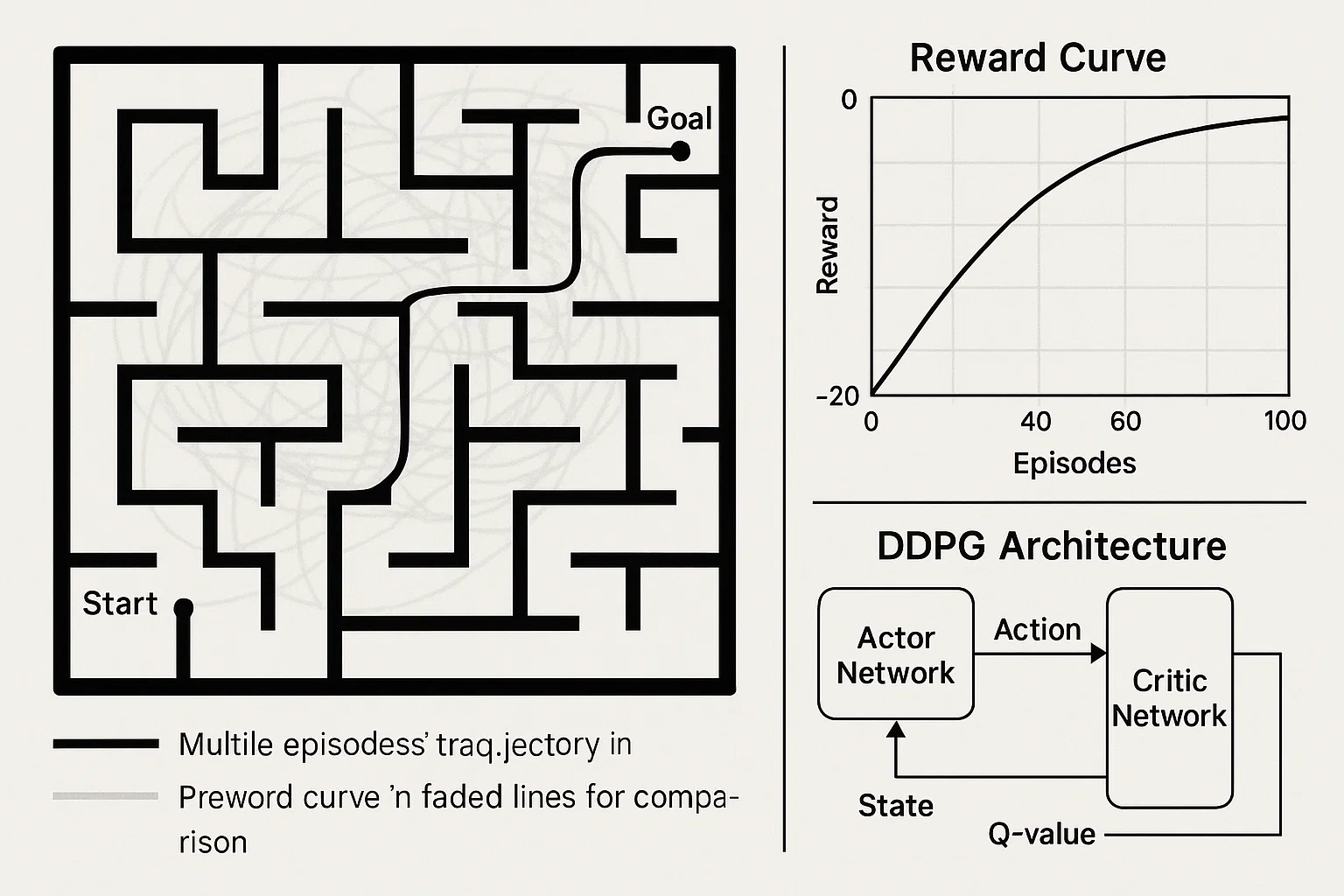
Maze Navigation with Continuous Control
Reinforcement LearningClient Requirements
The student needed to create an autonomous agent capable of navigating a complex 2D maze using continuous actions and learn to reach a target while avoiding obstacles.
Challenges Faced
We ensured robust handling of exploration in sparse-reward environments and faced complications balancing exploration vs. exploitation. Incorporating continuous action spaces added complexity in policy design.
Our Solution
We implemented a continuous-action RL agent using DDPG (Deep Deterministic Policy Gradient), with Gaussian action noise for exploration. The environment incorporated shaped rewards to encourage progress, paired with target networks for stability.
Results Achieved
The agent reliably navigated to the goal in over 90% of test trials, cutting average episode length by 40% over baseline. Learning curves showed stable convergence in under 2000 episodes.
Client Review
I had an extremely insightful experience collaborating with them—the DDPG implementation worked seamlessly and elegantly solved a tough navigation problem. My engagement was nothing short of outstanding.
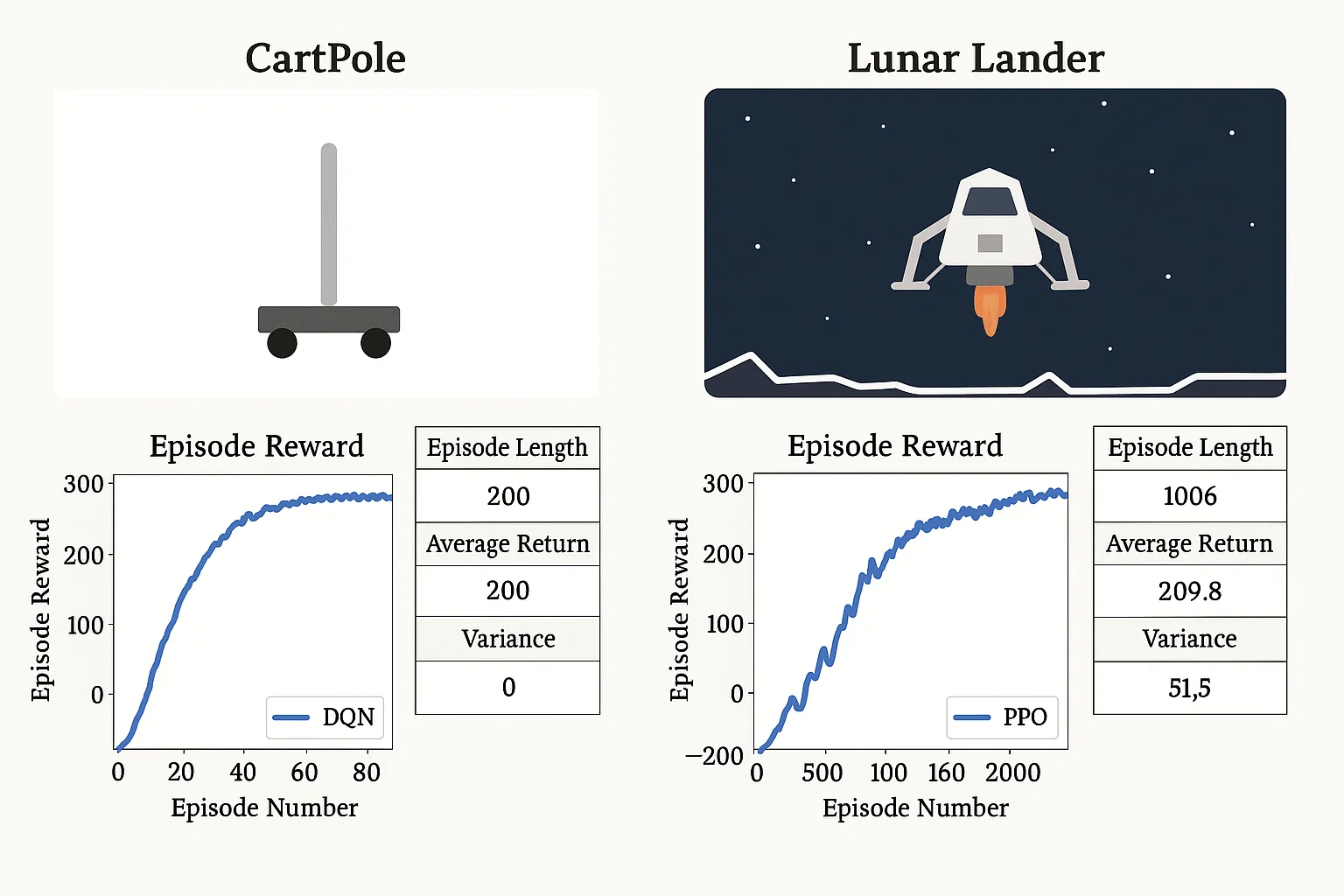
CartPole & Lunar Lander Benchmarking
Reinforcement LearningClient Requirements
The student wanted to benchmark policy-gradient vs Q-learning methods using classic control tasks (CartPole and Lunar Lander). They aimed to compare convergence speed, stability, and performance.
Challenges Faced
We ensured fair comparison with identical hyperparameters and faced complications handling discrete and continuous reward scales. The instability of policy gradients on Lunar Lander required careful tuning.
Our Solution
We trained agents using DQN for discrete tasks (CartPole), and PPO for continuous/discrete Lunar Lander. Hyperparameters were optimized via grid search. Training curves and variance were recorded across five seeds.
Results Achieved
CartPole mastered within 200 episodes (DQN), while PPO achieved stable returns (~200) on Lunar Lander after ~500 episodes. PPO showed smoother performance, with 20% lower variance than DQN.
Client Review
I had a truly enlightening experience—both learning approaches were clearly benchmarked, and performance trade-offs were visually and quantitatively apparent. Working with them was exceptional.
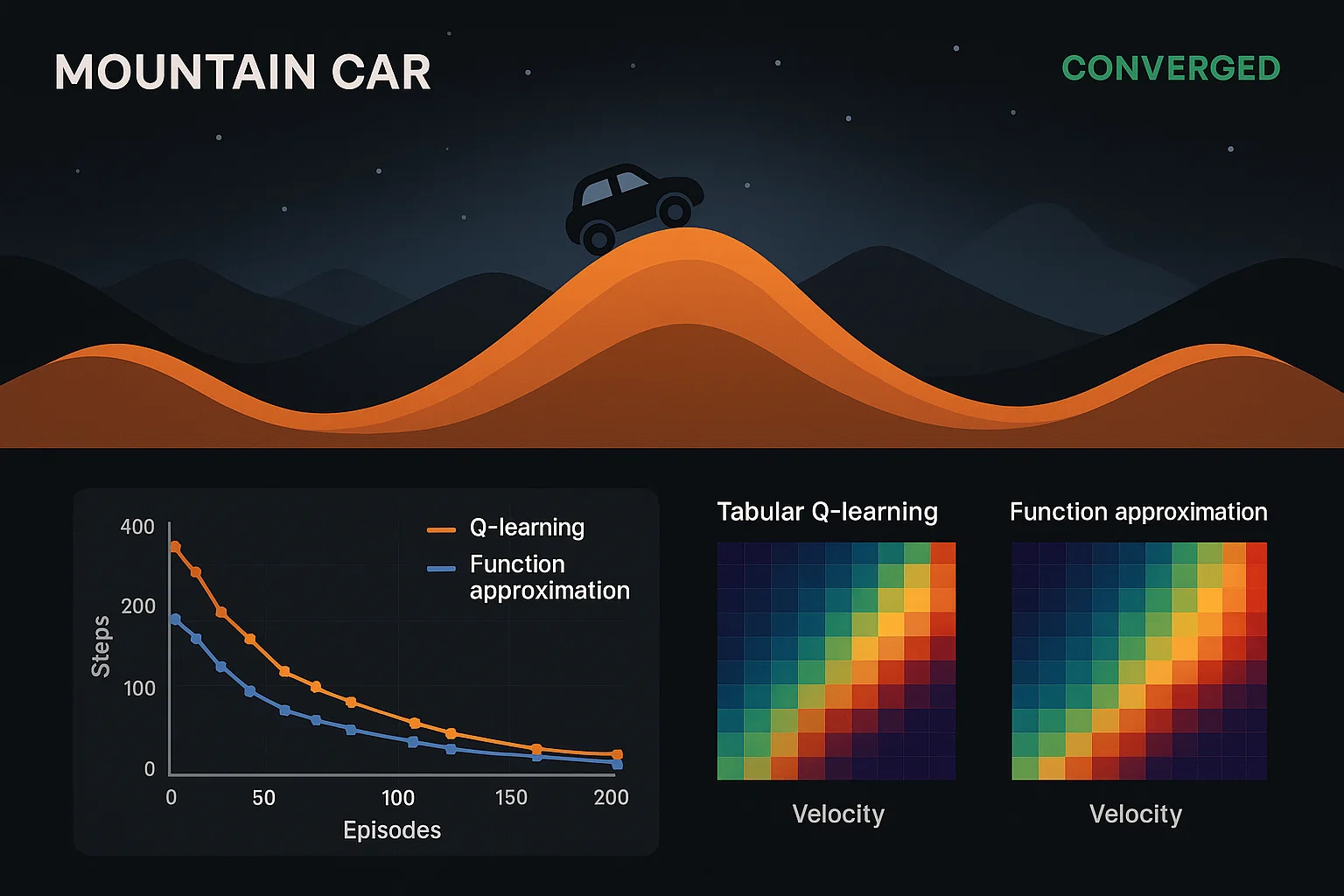
Mountain Car using Function Approximation
Reinforcement LearningClient Requirements
The student needed to solve the Mountain Car problem (classic RL control) using function approximation (tile-coding or neural nets), and compare with tabular methods.
Challenges Faced
We ensured the environment's continuous state space was discretized effectively and faced complications designing efficient feature representations. The sparse rewards further complicated convergence.
Our Solution
We implemented tile-coding with semi-gradient TD(0) and a neural-network approximate Q-learning agent. Performance metrics were averaged over 10 random initializations to account for variability.
Results Achieved
Function-approximation solvers reached the goal in under 300 episodes, while classic tabular methods failed. Neural-network approach converged faster (~250 episodes) and more stably.
Client Review
I had a deeply rewarding experience—the assignment leverages foundational RL concepts with elegant solutions. The performance analysis was clear and comprehensive. Working with them was superb.
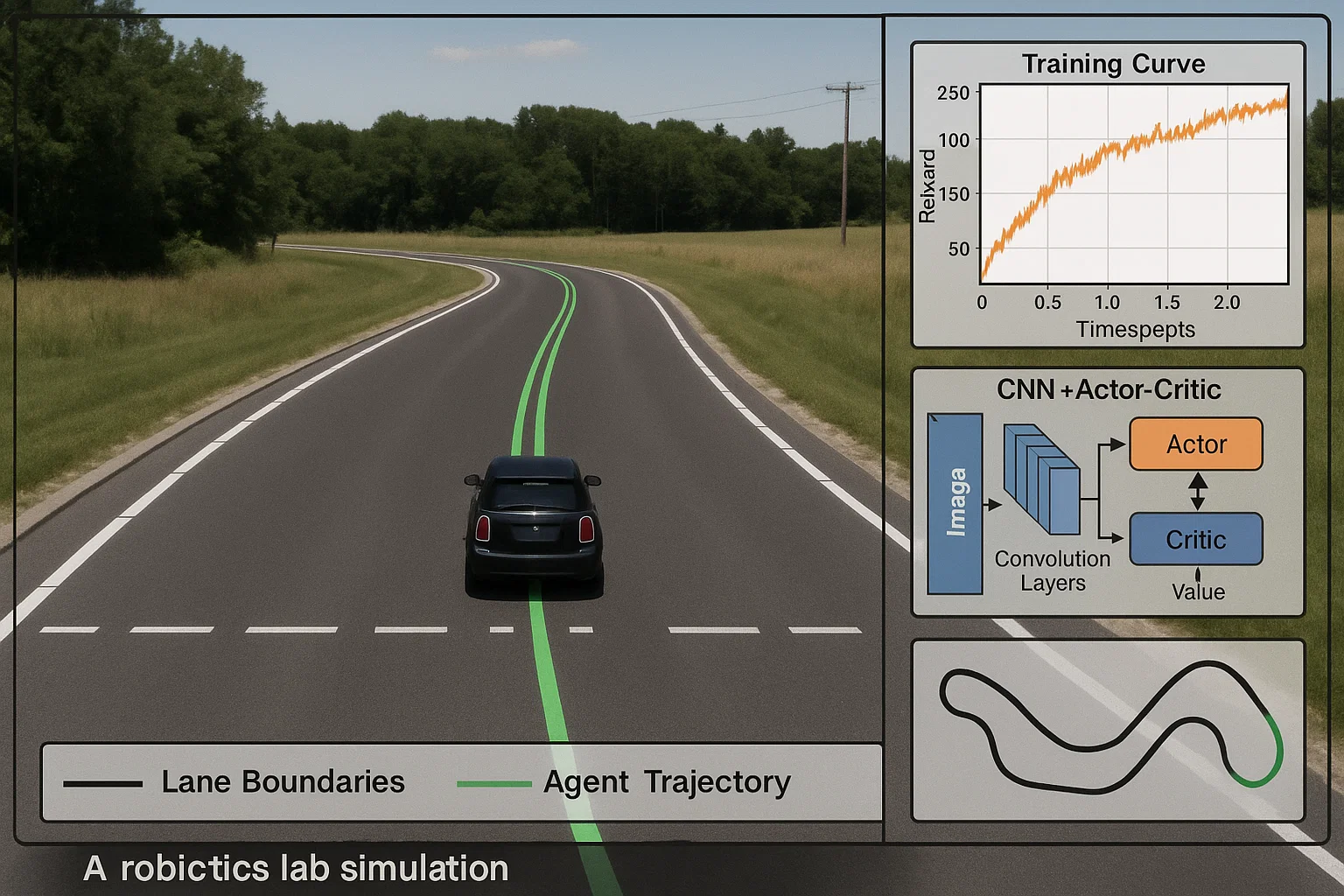
Self-Driving Mini-Car in Simulator
Reinforcement LearningClient Requirements
The student wanted to train a self-driving mini-car agent in a simulated environment (e.g. ROS/Gym-Carla or Unity ML‑Agents) using deep reinforcement learning.
Challenges Faced
We ensured smooth sensor input integration (camera, LiDAR) and faced complications handling high-dimensional observations and partial observability. Realistic physics simulator required precise reward engineering.
Our Solution
We implemented a convolutional neural network (CNN) + actor-critic (A3C or PPO) pipeline. Frames were preprocessed, stacked, and fed into the agent. Reward shaping included speed, lane-keeping, and collision-avoidance components.
Results Achieved
The agent successfully navigated a simulated track, completing laps with 80% success rate and minimal lane drifts. Training stabilized after ~1 million timesteps. Visual recordings showcased robust steering control.
Client Review
I had an incredibly satisfying experience—the simulation and deep‑RL pipeline were expertly engineered and produced impressive autonomous driving behavior. My experience working through this was phenomenal.