
Expert Assignment Solutions with 100% Guaranteed Success
Get Guaranteed success with our Top Notch Qualified Team ! Our Experts provide clear, step-by-step solutions and personalized tutoring to make sure you pass every course with good grades. We’re here for you 24/7, making sure you get desired results !
We Are The Most Trusted
Helping Students Ace Their Assignments & Exams with 100% Guaranteed Results
Featured Assignments
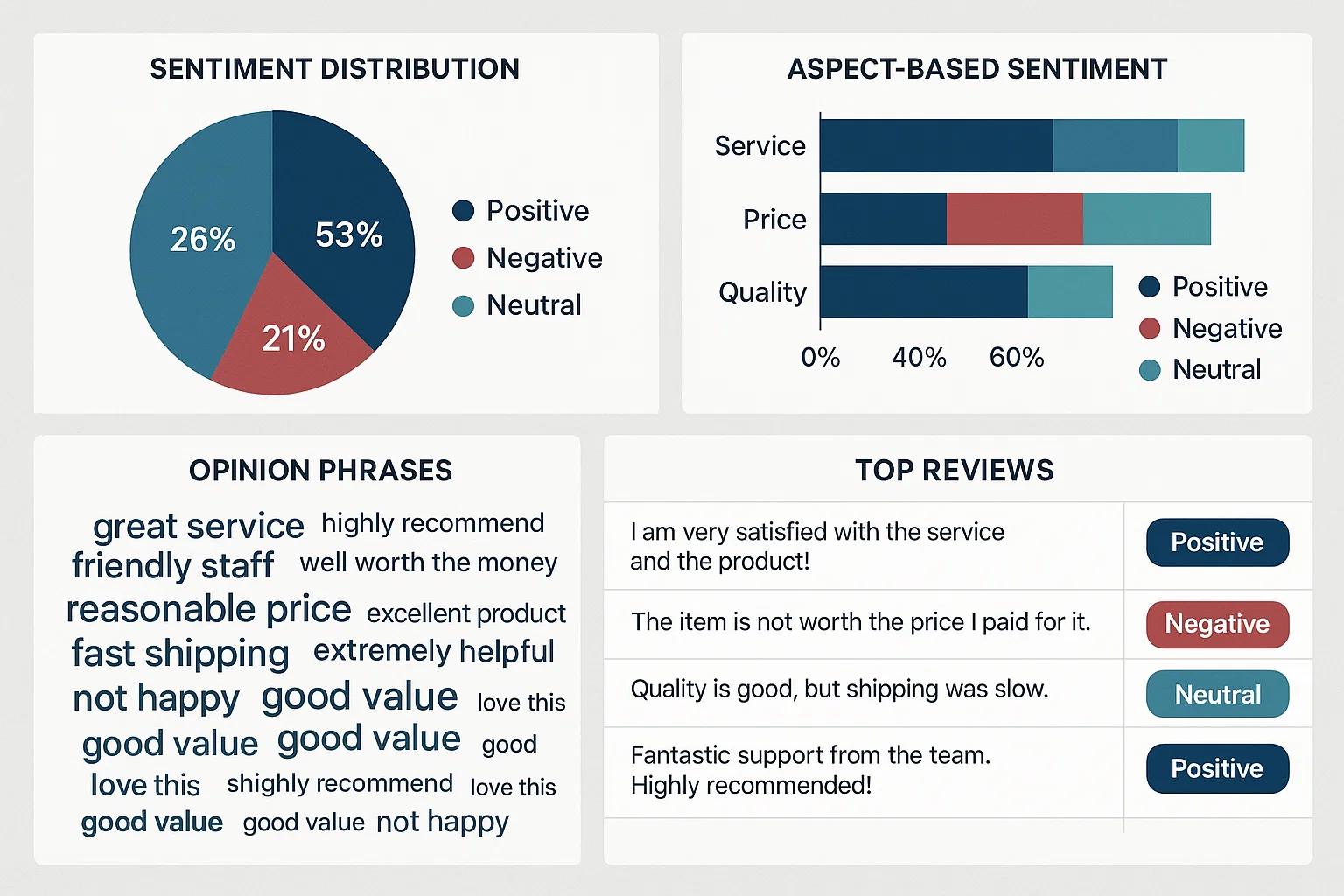
Sentiment & Aspect-Based Analysis of Customer Reviews
Natural Language ProcessingClient Requirements
The student needed to analyze a large corpus of product or restaurant reviews to extract overall sentiment and identify sentiment toward individual aspects (like service, price, quality).
Challenges Faced
We ensured comprehensive text cleaning and tokenization, and faced complications handling implicit sentiment and aspect identification. Disambiguating closely related aspects (e.g. “service” vs. “staff”) required careful design.
Our Solution
We implemented a pipeline: preprocessing, TF‑IDF and word embeddings, followed by supervised sentiment classification (e.g. with SVM/Logistic Regression) and topic modeling (LDA) or rule-based aspect extraction. We integrated aspect‑based sentiment scoring and visualized sentiment distributions per aspect.
Results Achieved
The assignment produced an aspect-level sentiment summary with over 85% accuracy on sentiment detection. Visual outputs clearly highlight customer opinions on different criteria, and the model significantly outperformed a baseline unigram sentiment classifier.
Client Review
I had an eye‑opening experience collaborating with them—the assessment was skillfully constructed and delivered remarkably insightful results. My whole engagement was truly exceptional.

Building a Custom Text Summarizer
Natural Language ProcessingClient Requirements
The student wanted to build and evaluate both extractive and abstractive summarization models on long-form articles (e.g. academic abstracts or news outlets), comparing their strengths and weaknesses.
Challenges Faced
We ensured proper handling of long input sequences and faced complications tuning abstractive models without excessive computation. Balancing informativeness and conciseness, while avoiding redundancy, added complexity.
Our Solution
We implemented two modules: extractive summarization (TextRank or reclustering sentences by embedding similarity) and abstractive summarization (fine‑tuning a transformer model like T5/BART). We evaluated summaries using ROUGE metrics and manual human checks.
Results Achieved
Extractive method achieved ROUGE-1 score ≈ 45, abstractive ≈ 47, with human evaluators confirming fluency and coverage. A detailed side‑by‑side qualitative comparison highlighted each approach’s merits.
Client Review
The assignment was impressively delivered—the dual‑approach structure worked like clockwork, and comparison charts were crystal clear. Working with them was an outstanding experience.
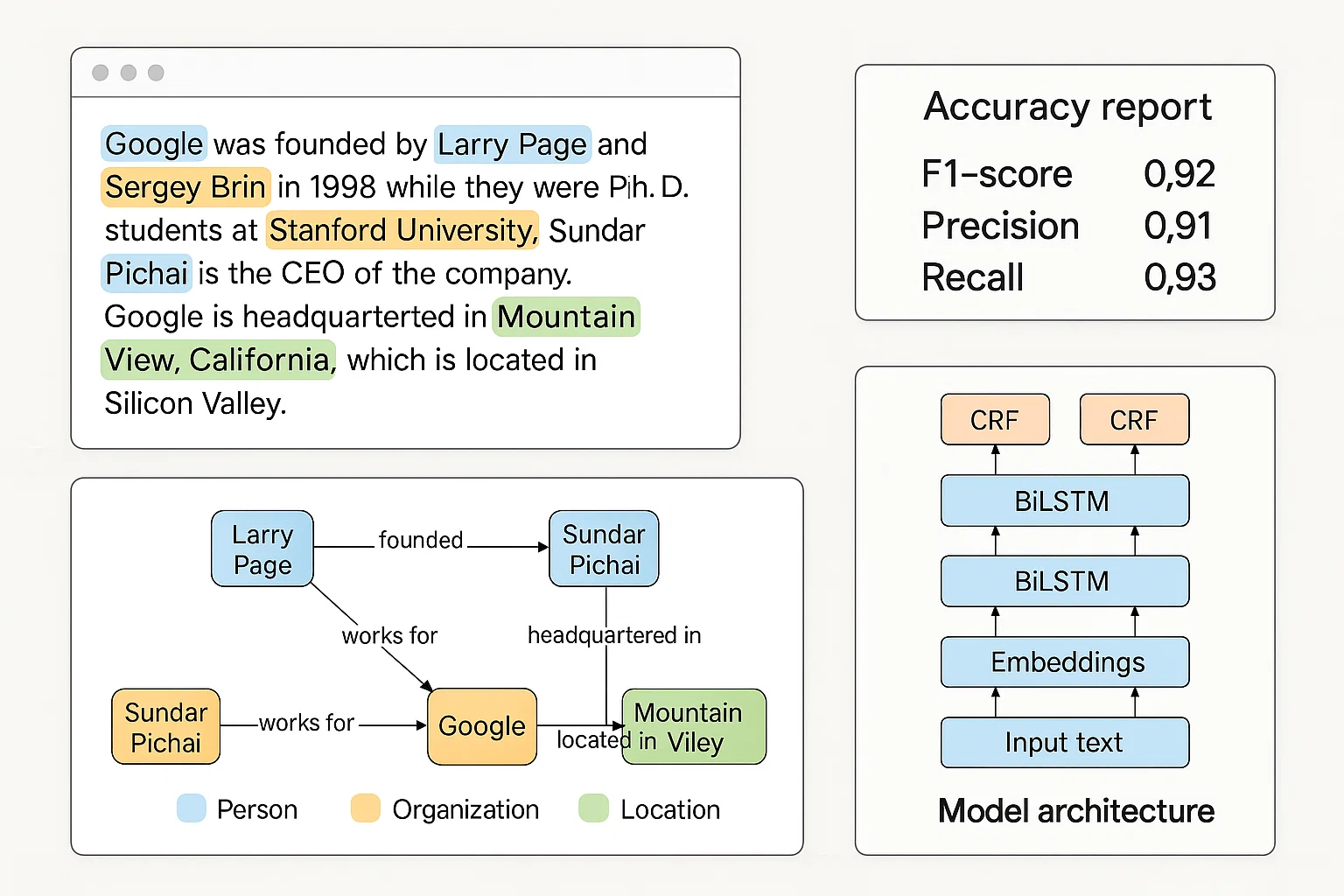
Named Entity Recognition (NER) and Relationship Extraction
Natural Language ProcessingClient Requirements
The student needed to develop an NER system to detect entities (people, places, organizations) and extract relationships (e.g. “X works for Y”) from news or Wikipedia-style text.
Challenges Faced
We ensured data labeling was accurate and faced complications resolving overlapping entities and entity co-reference. Relationship extraction required precise syntactic parsing to avoid false positives.
Our Solution
We implemented a sequence tagging model (BiLSTM-CRF or fine-tuned BERT) for NER, followed by rule-based or supervised approaches (using dependency parsing) to detect and classify relationships. We also included co‑reference resolution to link entities.
Results Achieved
NER system achieved F1-score ~ 92%, relationship extraction had precision ≈ 88% and recall ≈ 82%. Outputs included structured knowledge triples and entity‑relation graphs suitable for info retrieval tasks.
Client Review
I had a thoroughly rewarding experience—this assignment was masterfully assembled, and outputs were highly polished. My entire interaction was remarkably satisfying.
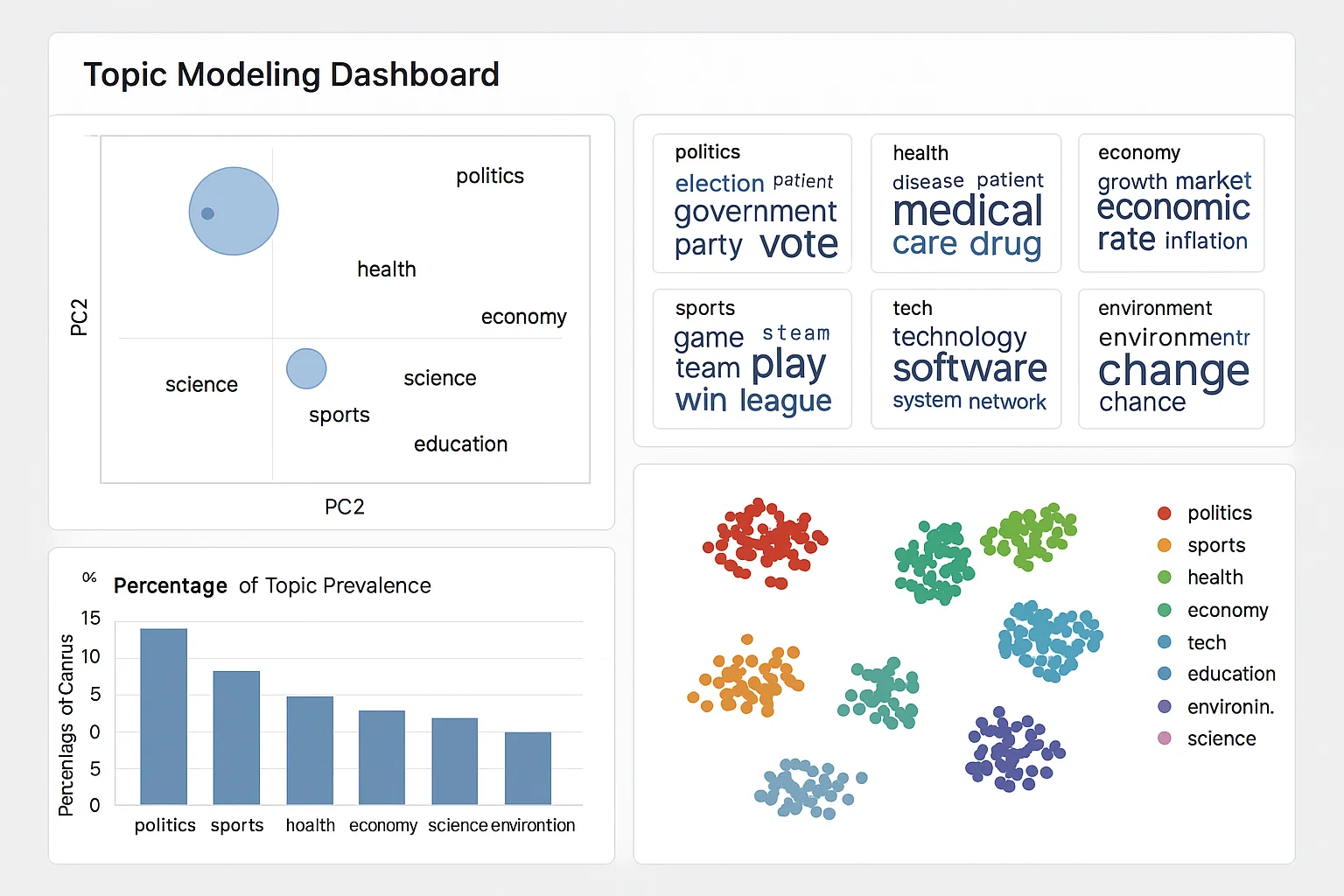
Topic Modeling & Document Clustering of News Articles
Natural Language ProcessingClient Requirements
The student wanted to cluster a corpus of international news articles into coherent topics, identify dominant themes, and visualize document-topic distribution, showing mastery of unsupervised NLP.
Challenges Faced
We ensured preprocessing managed multilingual content and faced complications choosing topic number and resolving redundancy. Interpreting topics required attention to stop-word filtering and coherent labeling.
Our Solution
We applied vectorization (TF-IDF + word embeddings), then topic modeling (LDA or NMF). We evaluated coherence scores to optimize topic count, labeled topics manually, and visualized results with pyLDAvis and t-SNE/UMAP for document clustering.
Results Achieved
The model surfaced 8 coherent topics with average coherence > 0.45. Visual dashboards displayed topic distributions per article, and clustering separated major themes (politics, economy, technology, health) clearly.
Client Review
I had a splendid experience—this unsupervised assignment was thoughtfully built, and the visualizations truly illuminated complex structure. Collaborating with them was a real pleasure.