
Expert Assignment Solutions with 100% Guaranteed Success
Get Guaranteed success with our Top Notch Qualified Team ! Our Experts provide clear, step-by-step solutions and personalized tutoring to make sure you pass every course with good grades. We’re here for you 24/7, making sure you get desired results !
We Are The Most Trusted
Helping Students Ace Their Assignments & Exams with 100% Guaranteed Results
Featured Assignments
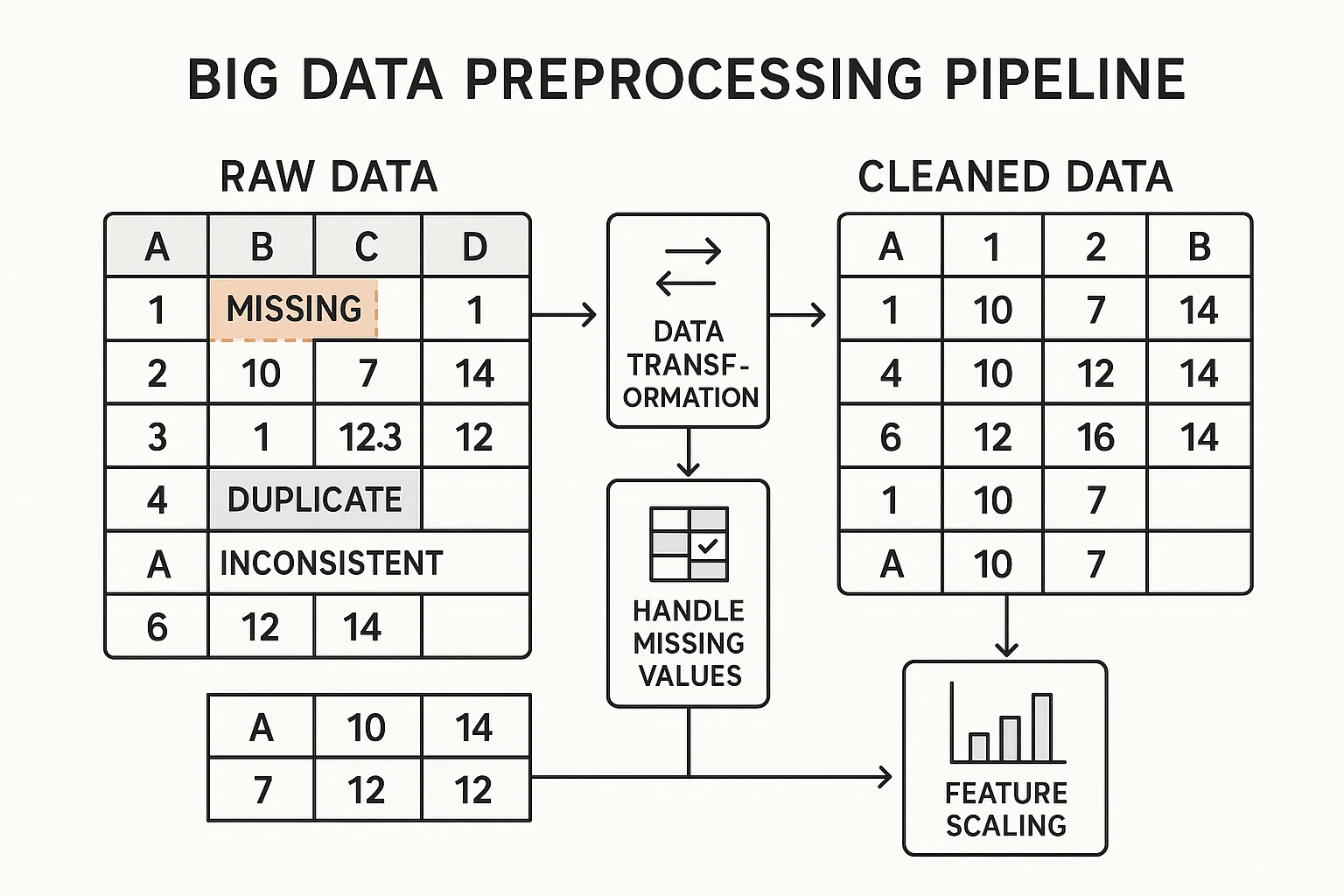
Data Acquisition and Preprocessing Pipeline
Big Data AnalyticsClient Requirements
The student needed to design and implement a data acquisition and preprocessing pipeline capable of handling large-scale datasets. This involved setting up data ingestion from multiple sources, cleaning the data, and transforming it into a suitable format for analysis.
Challenges Faced
We ensured that the dataset included various data quality issues, such as missing values, duplicates, and inconsistencies, to test the student's ability to handle real-world data. The student faced complications in choosing appropriate preprocessing techniques and justifying their choices.
Our Solution
We implemented a structured approach using tools like Apache Kafka for data ingestion, Apache Spark for data processing, and Python libraries such as Pandas for data cleaning and transformation. The student was guided to handle missing values through imputation, remove duplicates, and standardize data formats.
Results Achieved
The student successfully developed a scalable data pipeline that efficiently ingested, cleaned, and transformed large datasets, ensuring they were ready for analysis. This assignment enhanced their understanding of the importance of data preprocessing in big data analytics.
Client Review
Collaborating with them was a seamless experience. The assignment was meticulously structured, and the guidance provided was instrumental in navigating the complexities of data preprocessing.
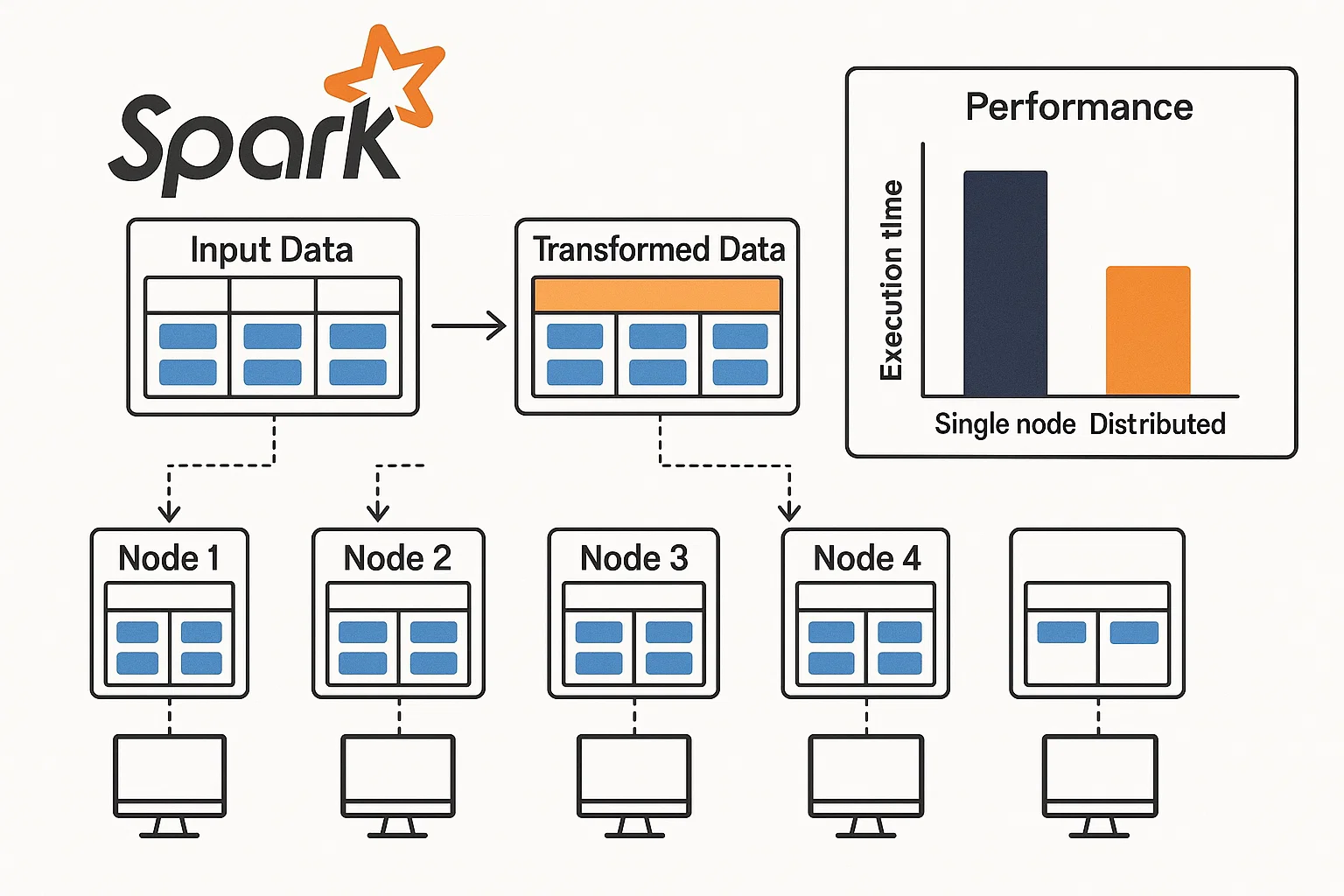
Distributed Data Processing with Apache Spark
Big Data AnalyticsClient Requirements
The student wanted to process a large dataset using distributed computing techniques. This involved setting up an Apache Spark cluster, implementing data transformations, and performing computations across multiple nodes.
Challenges Faced
We ensured that the dataset was large and complex, containing various data types and structures, to test the student's ability to apply distributed processing techniques effectively. The student faced complications in optimizing Spark jobs for performance and managing resources across the cluster.
Our Solution
We guided the student to set up a Spark cluster using tools like Hadoop YARN or Kubernetes for resource management. The student was instructed to implement data transformations using Spark's RDDs and DataFrames, and to optimize Spark jobs by tuning parameters such as partitioning and caching.
Results Achieved
The student successfully processed the large dataset in a distributed manner, achieving significant performance improvements over traditional single-node processing. This assignment deepened their understanding of distributed computing in big data analytics.
Client Review
Their approach to the assignment was thorough and insightful. The feedback provided was constructive, helping me to refine my understanding of distributed data processing techniques.
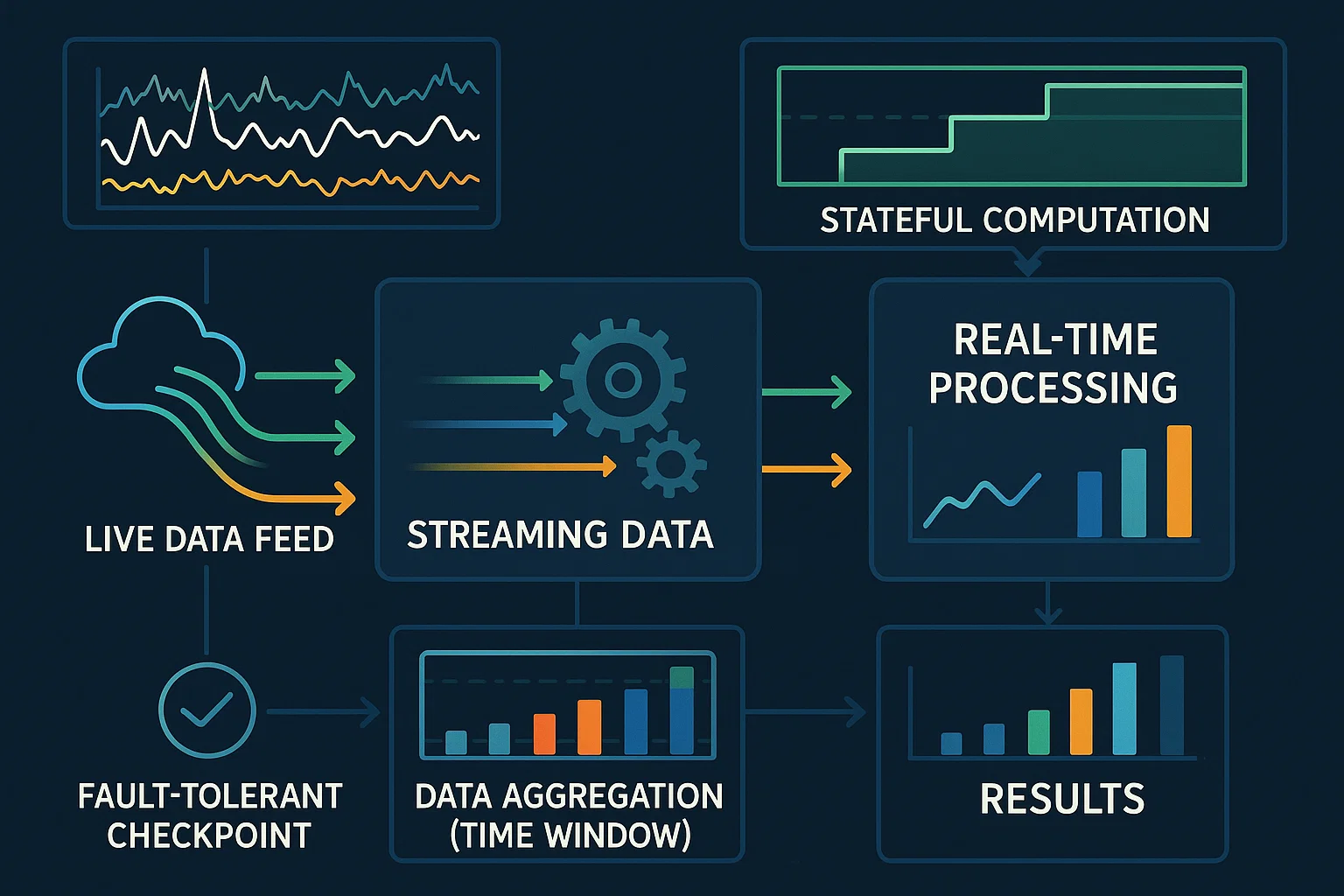
Real-Time Data Stream Processing
Big Data AnalyticsClient Requirements
The student needed to design and implement a real-time data stream processing system. This involved setting up data ingestion from streaming sources, processing the data in real-time, and storing the results for further analysis.
Challenges Faced
We ensured that the data streams were continuous and high-velocity, to test the student's ability to handle real-time data processing challenges. The student faced complications in managing stateful computations and ensuring fault tolerance in the streaming pipeline.
Our Solution
We guided the student to use Apache Kafka for data ingestion and Apache Flink or Spark Streaming for real-time data processing. The student was instructed to implement windowing, aggregations, and stateful operations, and to configure checkpoints for fault tolerance.
Results Achieved
The student successfully developed a real-time data processing system that ingested, processed, and stored streaming data with low latency, enabling timely insights. This assignment enhanced their understanding of real-time analytics in big data environments.
Client Review
I had an enriching experience working with them. The assignment was well-structured, and the resources provided were instrumental in completing the task efficiently.
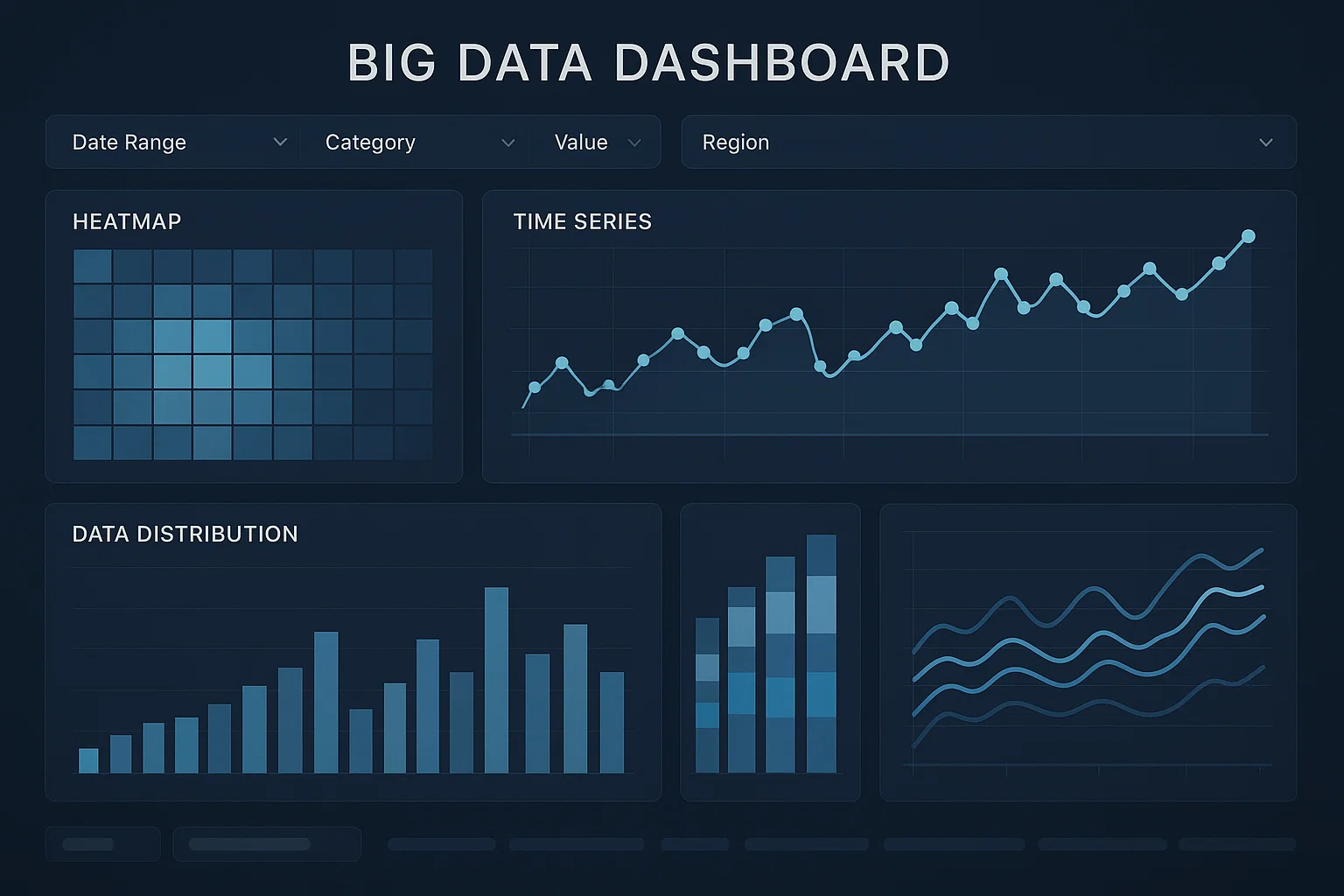
Big Data Visualization and Dashboarding
Big Data AnalyticsClient Requirements
The student wanted to create interactive visualizations and dashboards to represent insights from a large dataset. This involved selecting appropriate visualization techniques, implementing them using big data visualization tools, and integrating them into a cohesive dashboard.
Challenges Faced
We ensured that the dataset contained complex relationships and patterns, to test the student's ability to choose and apply suitable visualization techniques. The student faced complications in handling large-scale data for visualization and ensuring the responsiveness of the dashboard.
Our Solution
We guided the student to use tools like Apache Superset, Tableau, or Power BI for creating interactive dashboards. The student was instructed to implement visualizations such as heatmaps, time series plots, and bar charts, and to optimize the dashboard for performance and user interactivity.
Results Achieved
The student successfully developed an interactive dashboard that effectively visualized insights from the large dataset, facilitating data-driven decision-making. This assignment deepened their understanding of data visualization in big data analytics.
Client Review
Working with them was a rewarding experience. The assignment challenged me to apply theoretical knowledge to practical scenarios, enhancing my understanding of big data visualization techniques.