
Expert Assignment Solutions with 100% Guaranteed Success
Get Guaranteed success with our Top Notch Qualified Team ! Our Experts provide clear, step-by-step solutions and personalized tutoring to make sure you pass every course with good grades. We’re here for you 24/7, making sure you get desired results !
We Are The Most Trusted
Helping Students Ace Their Assignments & Exams with 100% Guaranteed Results
Featured Assignments
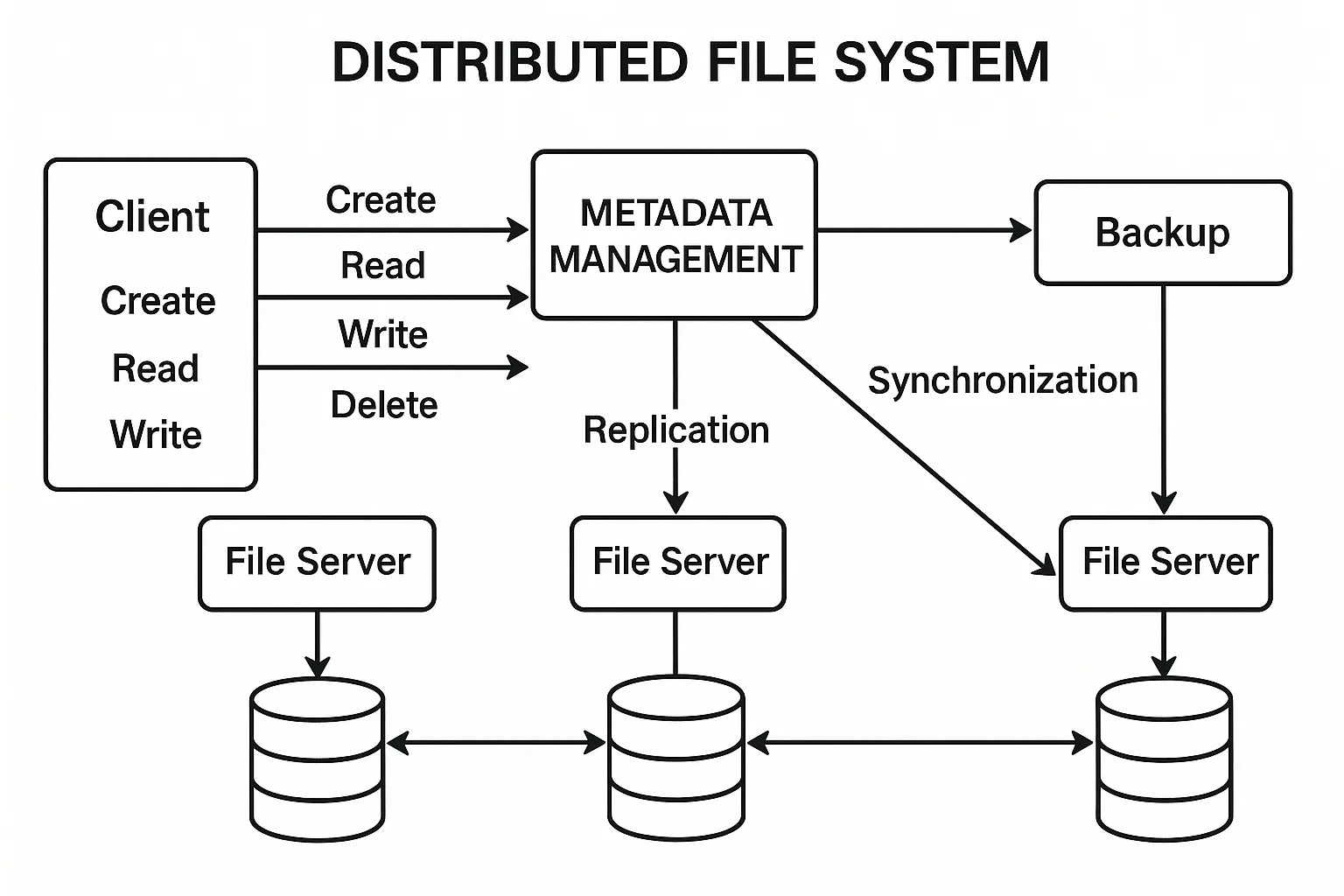
Implementing a Distributed File System
Distributed Systems and File ManagementClient Requirements
The student needed to design and implement a distributed file system (DFS) that supports basic file operations like create, read, write, and delete. The task required the student to implement replication and fault tolerance to ensure that files are available even if some nodes fail. The system should also support metadata management and provide consistency across nodes, ensuring that updates to files are synchronized correctly.
Challenges Faced
We ensured that students understood the core principles behind distributed systems, but many faced complications in implementing fault tolerance and managing replication. Some students struggled with the complexities of maintaining consistency across nodes and dealing with issues like network partitioning. Balancing performance with reliability, especially in a distributed environment, also posed difficulties.
Our Solution
We introduced students to well-established DFS protocols such as HDFS or NFS and guided them in applying principles of replication, fault tolerance, and consistency. Students were encouraged to implement a simple client-server architecture for file storage, with background processes handling data replication and synchronization. Additionally, we introduced consistency models like eventual consistency and strong consistency to help them make informed design decisions.
Results Achieved
The students successfully designed and implemented a functioning DFS, ensuring data availability and consistency. They demonstrated their understanding of distributed file management, with the system performing well under both normal and failure conditions. Many students also added extra features like load balancing and optimized synchronization protocols to improve performance.
Client Review
My experience with this assignment was both challenging and highly rewarding. Designing a distributed file system and implementing replication and fault tolerance made me realize how complex real-world distributed systems are. The guidance I received allowed me to tackle these challenges step by step, and I now feel much more confident in building and understanding distributed systems.
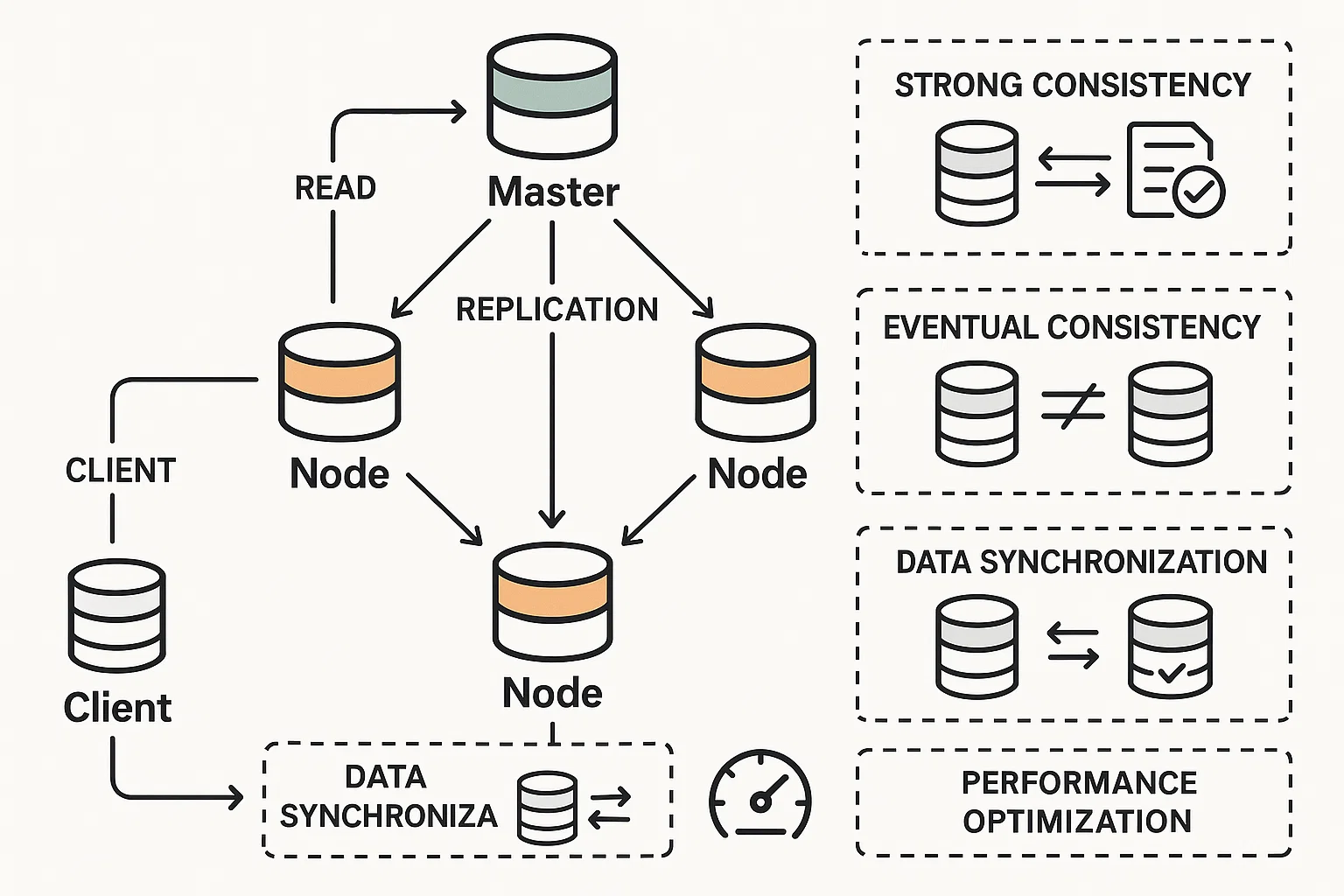
Building a Distributed Database with Replication
Distributed Databases and ReplicationClient Requirements
The student wanted to build a distributed database system that supports data replication and can handle queries from multiple clients simultaneously. The task required the student to implement a replication strategy to ensure that data is consistent and available even in case of failures. The student was also asked to optimize query performance and handle conflict resolution when data is updated in different nodes.
Challenges Faced
We ensured that students grasped the complexities of distributed databases, but they faced challenges in designing a replication mechanism that was both efficient and fault-tolerant. Students struggled with ensuring that data updates were properly synchronized across replicas and dealing with conflicts arising from concurrent writes. Additionally, optimizing query performance in a distributed environment required significant effort.
Our Solution
We guided students in choosing a suitable consistency model (such as eventual consistency or strong consistency) and a replication strategy (e.g., master-slave, peer-to-peer). Students were shown how to implement basic data replication mechanisms, such as synchronous and asynchronous replication, and were introduced to conflict resolution strategies. We also covered indexing and query optimization techniques for distributed databases to enhance performance.
Results Achieved
The students successfully created a distributed database that handled replication and synchronization efficiently. Their systems were able to perform queries correctly, even when replicas were updated concurrently, and they successfully addressed conflict resolution. Students also implemented basic optimizations that improved query response time, demonstrating their understanding of distributed systems and database design.
Client Review
This assignment was a great way to learn about distributed databases. Implementing replication and conflict resolution was tough at first, but the resources and guidance provided helped me overcome these challenges. The experience of building a distributed system that can handle real-time queries and data synchronization has given me a solid understanding of how distributed databases work in practice.
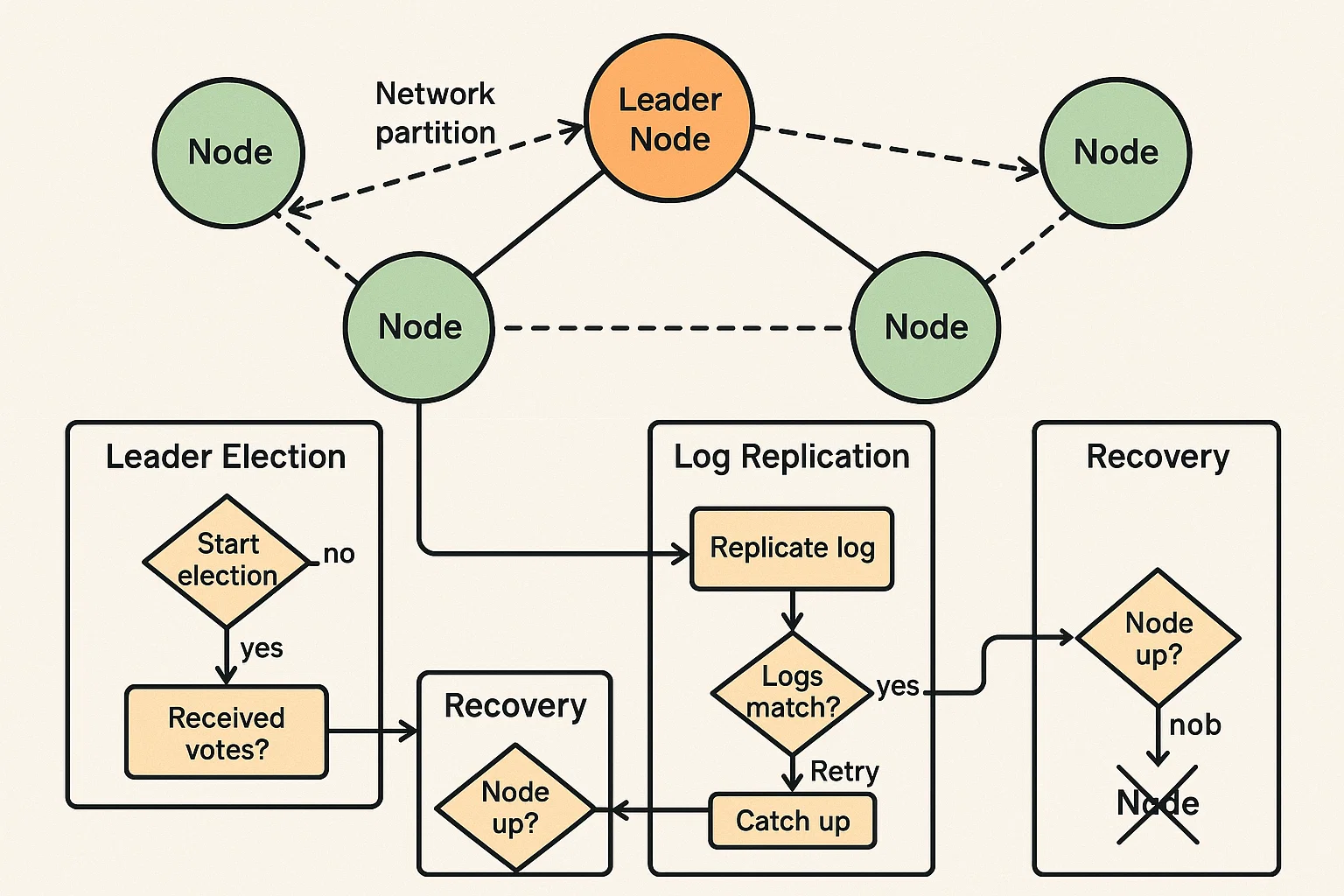
Implementing a Distributed Consensus Algorithm
Distributed Consensus and Fault ToleranceClient Requirements
The student needed to implement a distributed consensus algorithm, such as Paxos or Raft, that ensures a group of nodes can agree on a single value, even in the presence of failures. The task required them to simulate a distributed system where nodes communicate to reach a consensus on a decision, such as agreeing on the leader node or a configuration change. The system should handle failures, network partitions, and ensure data consistency.
Challenges Faced
We ensured that students understood the theoretical background of consensus algorithms, but many struggled with the complexity of implementing these algorithms. Some faced difficulties in handling network partitions and ensuring that the system could recover from crashes or failures while maintaining consistency. Debugging distributed systems and ensuring that all nodes reached a consensus without deadlock or split-brain scenarios proved to be a significant challenge.
Our Solution
We provided a detailed explanation of consensus algorithms and the key concepts of leader election, quorum, and fault tolerance. Students were given step-by-step instructions on how to implement basic versions of Paxos or Raft, with emphasis on managing communication between nodes, ensuring log replication, and handling node failures. We also provided resources on simulating failures and testing the system’s behavior under different conditions.
Results Achieved
The students successfully implemented distributed consensus algorithms that allowed nodes to agree on decisions in the presence of failures. Their systems were resilient to network partitions and crashes, and they ensured that the system could always recover to a consistent state. Most students were able to handle edge cases such as network delays and failure recovery effectively.
Client Review
Implementing a consensus algorithm was a complex but rewarding challenge. The theoretical concepts behind Paxos and Raft were tough to grasp at first, but the guidance provided helped me piece everything together. By the end of the assignment, I had a deep understanding of how distributed systems handle consistency and fault tolerance, which is incredibly useful for designing resilient systems.
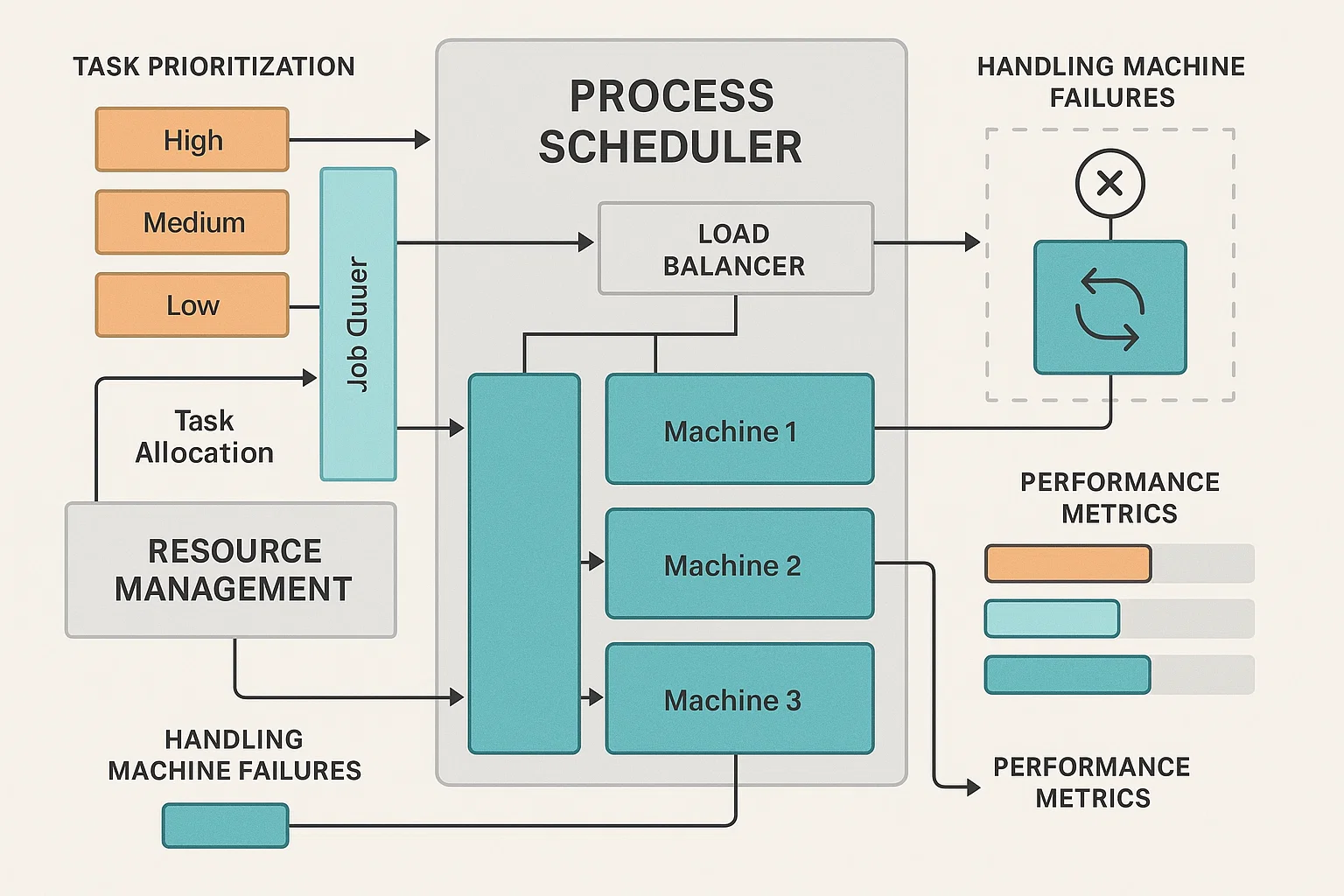
Designing and Simulating a Distributed Process Scheduler
Distributed Systems and Task SchedulingClient Requirements
The student needed to design and implement a distributed process scheduler for a system that manages tasks across multiple machines. The task required them to allocate resources, schedule processes, and manage job priorities in a way that ensures fairness and efficiency. The student was also asked to simulate fault tolerance and recovery in case of node failures or network delays.
Challenges Faced
We faced challenges in ensuring that students understood the intricacies of process scheduling in distributed environments. Some students struggled with resource allocation strategies, especially when dealing with heterogeneous machines or network delays. Handling task prioritization and fairness while maintaining efficiency under failure conditions required careful thought and planning.
Our Solution
We provided students with a framework for designing distributed schedulers, including algorithms for load balancing, task allocation, and recovery strategies. We introduced them to common scheduling algorithms like Round Robin and Priority Scheduling, with considerations for fairness and efficiency. Students were given practical examples to implement process scheduling algorithms in distributed systems, with simulated network delays and node failures to test their solutions.
Results Achieved
The students successfully designed and simulated distributed process schedulers that effectively managed tasks across multiple machines. They demonstrated an understanding of load balancing, fairness, and task prioritization, and their systems were able to recover from failures. The final systems were efficient and resilient, showcasing strong performance under different operating conditions.
Client Review
This assignment was very challenging, but it helped me understand how distributed systems manage tasks and resources. Implementing a process scheduler taught me how complex task allocation and load balancing can be in a distributed environment. The experience of simulating failures and ensuring the system could recover smoothly was especially valuable. I now have a much deeper understanding of distributed process management.